一次 JVM 占用 CPU 资源过高的问题排查
早晨刚到公司就收到服务器 CPU 持续飙高在 400% 左右的邮件。因为是新的服务器,上面只在一个 docker 中跑了一个 Java 应用,所以大致可以确定就是它的问题,接下来就是如何通过工具定位具体代码的问题了。大致的处理思路如下:
- 定位系统中引发问题的进程
- 定位进程中引发问题的线程
- 定位线程中引发问题的代码
如果能找到出问题的代码段,那么问题也就好解决了。
1. 定位引发问题的进程与线程
1) 使用 top 命令可找到问题进程的 PID
$ top
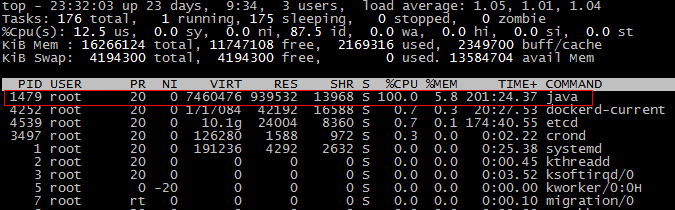
因为只有 docker 中的应用使用了 java 命令,所以确定就是它了。
2) 使用 docker stats 命令找到具体的容器 ID
$ sudo docker stats

可以看到 ID 为 af6b5699a590 的容器占用 CPU 很高。
3) 使用 docker exec & ps 命令找到容器中的应用 PID
$ sudo docker exec -it af6b5699a590 ps -ef

4) 使用 docker exec & top 命令找到出问题的线程的 PID
$ sudo docker exec -it af6b5699a590 top -H -p 1

这里的 PID 可用与在后面的 dump 文件中查找日志,但是需要将其从 10 进制转换为 16 进制,此处 56 的 16 进制为 0x38.
2. 定位代码段
5) 使用 docker exec 命令进入容器内部
$ sudo docker exec -it af6b5699a590 bash
6) 使用 jstack 打印线程的堆栈信息
保存到文件,并查找指定信息:
$ /jvm/java-11-openjdk-11.0.4.11-0.el7_6.x86_64/bin/jstack -l 1 > jstack_$(date "+%Y%m%d%H%M%S").txt
$ cat jstack_20190802062335.txt | grep -n -A 15 nid=0x38
或者直接输出:
$ /jvm/java-11-openjdk-11.0.4.11-0.el7_6.x86_64/bin/jstack -l 1 | grep -n -A 15 nid=0x38
(注:如果 docker 容器内只有 JRE,而没有 JDK,那么可以使用 docker cp 命令将本机的 JDK 拷贝至容器内。)
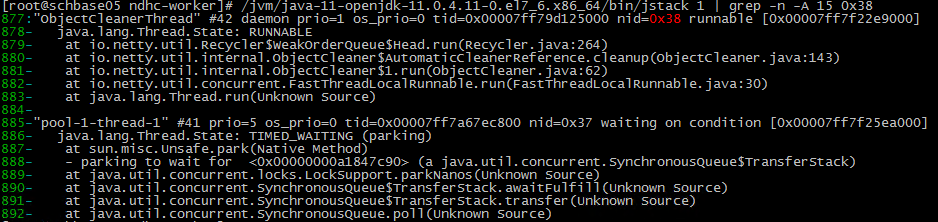
这里的 0x38 就是上面定位到的线程的 PID 的 16 进制,同时可以看到已经找到指定的代码行,那么问题极有可能就在这附近。
7) 追究问题的原因
根据关键字ObjectCleanerThread和netty可以很快速的搜索到相关的问题,同时根据上面的输出也能定位到源码:
@Override
public void run() {
Link head = link;
while (head != null) {
reclaimSpace(LINK_CAPACITY);
head = link.next;
}
}
以上代码片段来自于 netty-common 4.1.23.Final 中的 io.netty.util.Recycler&WeakOrderQueue$Head line 264,详情: https://github.com/netty/netty/blob/netty-4.1.23.Final/common/src/main/java/io/netty/util/Recycler.java#L264
而在新的版本(4.1.38.Final)中,已经没有上面的run()方法,取而代之的是多了一个finalize()方法,详情:https://github.com/netty/netty/blob/4.1/common/src/main/java/io/netty/util/Recycler.java#L265.
同时可参考关于此问题的一个讨论:https://github.com/grpc/grpc-java/issues/4495
最后通过升级相关 jar 包,问题得以解决。