数据同步项目总结2-数据流
数据流是指数据从源端存储库到目的端存储库的一个流动过程,这个过程与数据的有序性、吞吐量、安全点、统计等功能或特性息息相关,经过多次调整,最终在线上环境的测试中,单个作业的 SQLServer -> Kafka 的同步速度能够维持在 3800000+ rows、480M 每分钟的同步速度(线上环境硬件配置好,开发环境性能下降 3.5 倍左右),尽管多线程任务的数量没有刻意增大,但是这已经能满足大部分业务需求了,所以在这篇总结中,将记录数据流的一些设计。
一、数据流模型
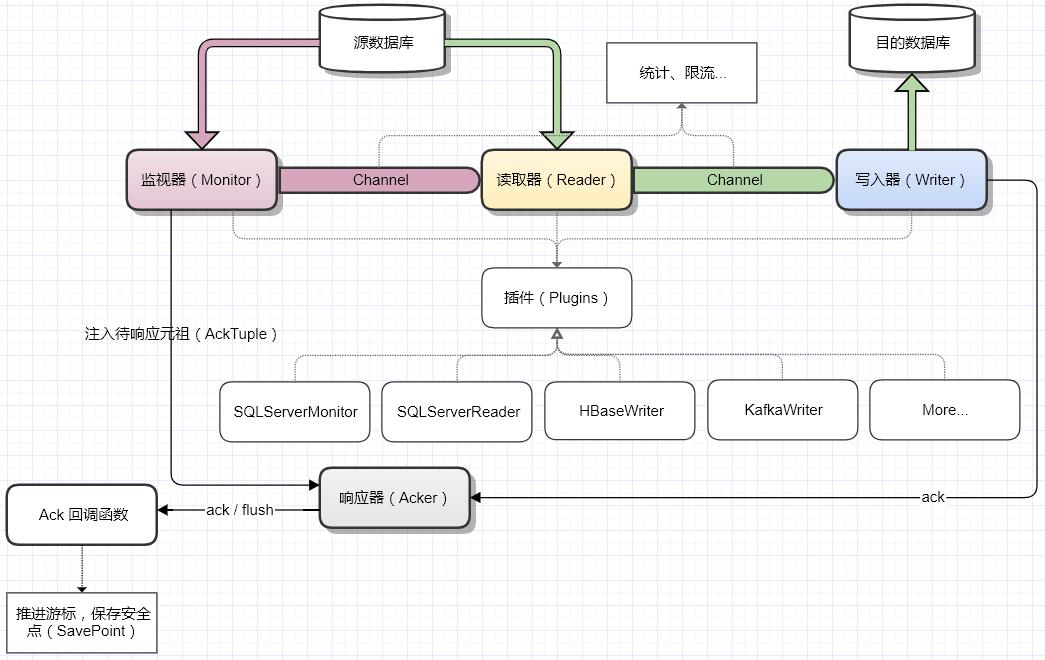
数据使用流式数据传输,核心原理是利用管道(Channel)实现异步传输,其中 Reader 负责读取源数据,每读取到一个源数据都会直接发送到管道,而 Writer 则会阻塞监听管道中的数据,每当接收到一个数据都会进行预处理,以准备写入,当数据达到一定数量或者达到一定时间后,数据再以批量写入的方式写入目的端。
因为是在线实时同步,所以 Monitor 的职责是负责数据变动监听,它的工作方式是主动拉取,比较适合像 SQLServer 这种只能通过 trigger、CT、CDC 的方式监听数据变动的源端,而如果是使用 MySQL binlog 主动推送的方式,则 Monitor 便不是必须的。以 SQLServer CT 为例,Monitor 通过轮询监听表的最新事务版本(Version),如果发现事务版本号发生变动,则从 CT 表中获取最新变动的数据主键信息(CT 表只存储主键),然后再将主键发送给 Reader 供其查询源数据。因为一个事务的数据量可能成百上千万,所以使用 Monitor 可以有效的将数据拆分,以使 Reader 能够进行多线程并发读取源数据。
而响应器(Acker)则主要用于处理数据写入成功后的响应,它保证了多线程环境下数据响应的有序性,即源端写入的顺序不论在多线程下如何变化,最终调用安全点更新的回调函数的顺序一定是与之一致的,因为只有这样,我们才能够保证安全点(或游标)的正确推进,很多系统也叫 checkPoint。
二、Ack 实现
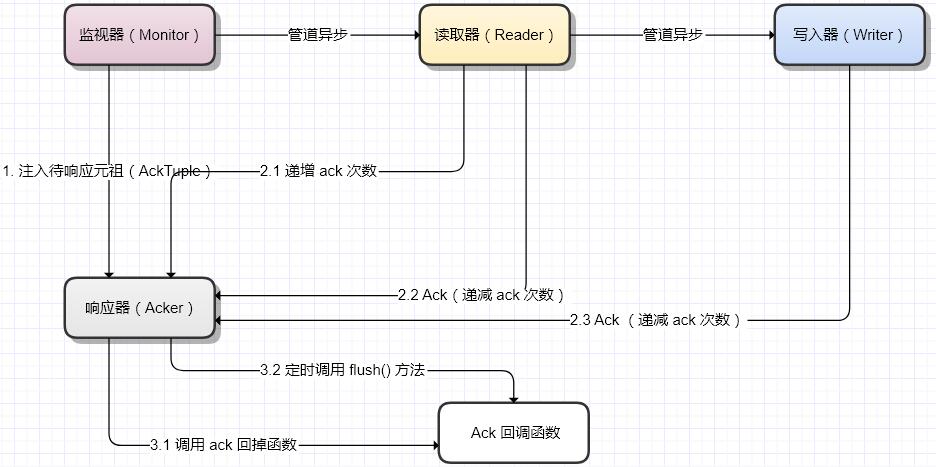
Ack 主要分为 3 个步骤:
- Monitor 监听到数据变动后注入一个 AckTuple,AckTuple 包含了一个有序的序列号、安全点、能够标识唯一行数据的主键或索引、响应次数(ack times)等信息。其中序列号用于维护 AckTuple 的顺序,主键或索引用于数据在经过二次处理后仍然能够定位对应的 AckTuple,响应次数用于处理数据在二次处理后的裂变、消失等情形下仍然能够正确的响应,即只有 ackTimes = 0 时才会调用回调函数;
- Reader 和 Writer 在处理完数据后都会调用 ack 函数,响应器则会通过计算 AckTuple 的响应次数,以及响应的顺序是否符合要求,而判断是否应该调用响应回调函数或者更新安全点。其中 Reader 在读取数据前都会递增 ackTimes,主要是防止数据的二次查询导致数据发生裂变或消失,所谓裂变是指监听到一条数据,最终却查询出多条数据,比如自定义 SQL 语句,而消失则意味着监听到数据,却没有查询出任何源数据。
- 在第3步中,ack() 是每次响应时(ackTimes=0)都会调用的回调函数,flush() 则是定时刷新,传入的参数包括最新的安全点,而这个安全点意味着在它之前的所有数据一定已经传输完毕。
Ack 的目的主要是为了解决多线程数据同步下的安全点推进问题,而多线程同步则是系统同步性能提升的一个关键因素。
三、线程模型
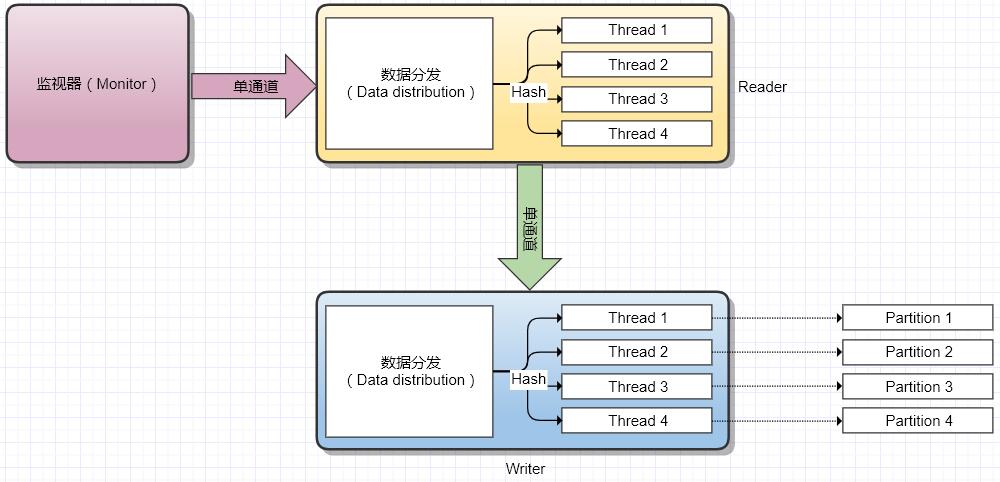
线程模型主要使用多线程 + 单通道模型,之所以使用单通道,是因为在在线同步的过程中,数据库(或其它存储库)的连接可能是一直存在的,而源端存储库与目的端存储库对于连接的要求也即可能是不一样的,所以通过单通道可以使 Reader 和 Writer 的线程数量互不影响,最终它们的连接也互不影响。比如 SQLServer -> Kafka 的数据同步中,它们的配置可能是 1 ~ 2 个数据读取线程 + 4 个数据写入线程。
数据通过通道进去 Reader 或者 Writer 后,通过 hash 主键计算将数据分发到对应线程,即能够保证相同主键的数据一定能够进入到相同的线程,最终也就保证了以主键为顺序的数据有序性。