数据同步项目总结1-数据实时同步的要点
这里的数据实时同步是指近乎实时的将数据从源端数据库同步到其它目的端数据库的一种方式,比如 MySQL 中的数据在发生变化时,系统能够尽可能实时的将这部分变化的数据同步到 HBase 中或其他目的端。与离线数据同步不同的是,数据实时同步面对的是随时都可能发生改变的数据,它除了需要保证数据能够正确到达目的端之外,还需要保证数据的正确性、时序性、可接受的延迟范围等情况,所以这篇博客主要用户记录数据实时同步过程中需要关注的一些关键点。
一、高效的数据同步模型
所谓高效,即既要保证高吞吐量,也要保证低延迟,这样才能保证即使源端数据变化量过大,也能尽可能短时间、实时的将数据传输到目的端。
而数据实时同步的最基本原理,就是将增量/变化数据从源端读出,然后再将数据写入目的端。在这中间则可以增加数据统计、转换、过滤、限流等功能,以此丰富数据同步的过程或适应更多的业务场景。那么我们应该如何保证这个过程的高效呢?
就我目前的了解一些同步系统而言,数据同步模型几乎都参考或类似于阿里 DataX 的数据同步模型,我喜欢叫它流式 + 批次的数据同步模型以及多任务多通道的线程模型。
流式 + 批次的数据同步模型
与传统的在单个线程中读取数据然后写入数据的流程不同,这里使用了流式计算的一些原理,数据的读取与写入分别位于两个独立的线程,它们通过管道(channel)传输数据。数据的读取方每读取到一个结果数据,都将其发送至管道,而数据的写入方每接收到一个新的结果数据,都会立即作出处理,这样做的一个好处在于,数据的写入方不必等待读取方的一次查询完成后才能开始处理数据,它可以在读取方读取数据的过程中,同时进行数据处理,尤其是数据读取可能需要经过多次网络传输时,这种方式能够更及时的处理数据。
批次数据处理的目的在于减少数据写入时的网络传输,不管是将数据写入 HBase 还是 Kafka 或其它目的端,合并多条数据并统一发送,都是减少网络传输以提高吞吐量的一种有效方式,所以数据写入方在处理完成一条数据后,通常都需要根据情况等待后面的数据,再统一发送。
多任务多通道/单通道的线程模型
多通道多任务的线程模型主要用于并发读取数据与写入数据,从而进一步提高系统的吞吐量,它的同步模型大致如下图所示:
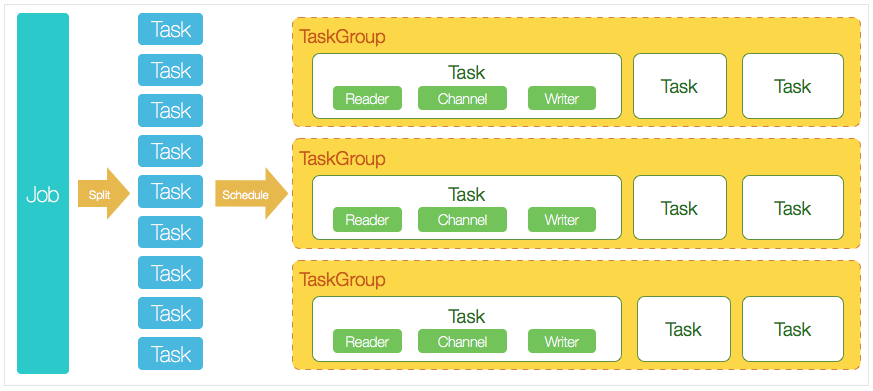
上图是阿里 DataX 的系统架构设计,虽然它是离线数据同步,但是数据同步模型却是类似的。一个 Job 被拆分成多个 Task,每个 Task 则负责与之对应的数据的读取与写入,Reader 对应数据的读取,Writer 对应数据的写入,它们运行在相互独立的线程之中,通过 Channel 传输数据,每个 Reader、Writer、Channel 是一一对应的,所以我管它叫多通道多任务的数据同步模型。
与多任务多通道类似的另外一种模型,也是我在系统中应用的一种模型,即多任务单通道数据模型,它的同步模型大致如下图所示:
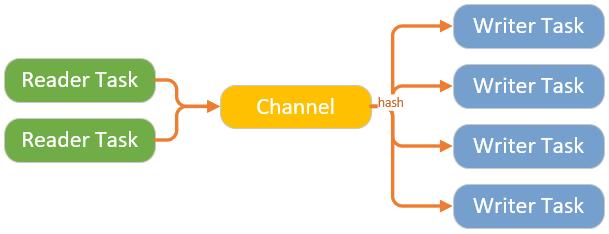
Reader 与 Writer 之间没有一一对应,而是公用一个 Channel,这样做的目的在于,因为源端读取数据与目的端写入数据的速度不一致,通过合理的配置 Reader 与 Writer 的任务数量,能尽可能的减少数据库连接数。
二、数据的一致性与时序性
数据的一致性是系统最基本的保障,不容有失。保证数据的一致性主要有两种依赖方式,一种是依赖于数据同步系统本身,在保证数据不丢失的前提下,通过将数据有序的传递给目的端,从而保证数据最终会达成与源端一致;二是依赖于目的端数据库的特性来实现,比如在 HBase 中,数据可以依赖于时间戳来确定数据是否为最新的,所以只需要在同步的过程中,针对每次操作都有固定的时间戳与之对应,那么不管操作顺序如何,只要最后的操作有应用在 HBase 之上,那么获取的数据总会是最新的。
上面提到的依赖于数据本身来保证数据的最终一致,应该是数据同步系统的一个最基本实现,因为我们不可能要求所有的目的端都能够像 HBase 那样,也不可能要求所有的数据都能传递一个固定的时间戳。那么这里就会涉及到一个操作顺序的问题,我们简单的将数据时序性分为两种类型:
- 数据全局有序,即不同行的数据的操作顺序必须与源端一致
- 数据以主键为单位的顺序一致,即仅保证单行数据的操作顺序必须与源端一致
1. 数据全局有序
数据全局有序是指数据的所有操作都按照先后顺序依次同步至目的端,即使不同数据行之间的操作顺序也必须一致。事实上,这样的业务场景相对比较罕见,如果真的需要满足这样的场景,那么通常的做法是将数据的读取与写入均设置为单任务即单线程模式,带来的影响是系统的吞吐量会相对变得低下。
2. 数据以主键为单位的顺序一致
数据以主键为单位的顺序一致是大多数业务场景需要的实现,同时它能使用多任务并发模式,有利于系统的吞吐量。而对于主键顺序一致,主要有两种情况:1) 数据可以回退,只需要保证数据的最终一致性;2) 数据不允许回退,只要更新为最新值后,便不能再更新回过去的值;
针对于上述两种情况,主要发生在系统异常时。在系统正常的情况下,数据的操作顺序应该总是有序的被应用于目的端,而异常的情况,主要是因为 Job 作为一个长期运行的作业,难免会发生重试的情况,比如对于 OP_1 -> OP_2 操作,可能会由于重试而产生 OP_1 -> OP_2 -> OP_1 -> OP_2 这样反复的操作,这就给时序性带来了一种新的可能。下面以 MySQL 和 SQLServer 为源端的数据同步为例。
- 在 MySQL 中,通常通过伪装从库并接收和解析 binlog 日志,来实现数据的监听和同步,此时拿到的是所有变更数据,它将直接被发送到目的端,所以当发生操作重发时,它的数据也会被重发,比如 OP_1(id=1, version=1) -> OP_2(id=1, version=2) 的两次操作,可能到目的端会变成 OP_1(id=1, version=1) -> OP_2(id=1, version=2) -> OP_1(id=1, version=1) -> OP_2(id=1, version=2) 的四次操作,其中 version 属性列会发生数据回退的现象;
- 在 SQLServer 中,因为它闭源的原因,通常使用 trigger 或者 CT/CDC 的方式来监听数据变动,为了减少系统负载, trigger 或者 CT 表中通常只会记录表的主键信息,在监听到数据变动时,会根据主键信息再去源表中查询全部所需的信息,此时对于 OP_1(id=1, version=1) -> OP_2(id=1, version=2) 的两次操作,可能到目的端会变成 OP_1(id=1, version=1) -> OP_2(id=1, version=2) -> OP_1(id=1, version=2) -> OP_2(id=1, version=2) 的四次操作,尽管操作发生了改变,但是数据却未发生回退现象。这种现象在《SQLServer 数据异构实时同步之数据时序的问题》中也有讨论过“数据操作的重复发送与影响”,在此不再熬述。
三、游标与断点续传
引起数据重发的原因,一方面是由于系统运行中,由于网络等原因引起的,另一方面也可能是由于手动停止然后再启动而引起的。对于手动停止或者异常停止,都会牵扯到断点续传的功能;
数据实时同步的过程是一个源源不断的将变化数据从源端流入目的端的过程,它可能会由于某种原因而中止同步,比如应用异常停止或者手动停止,不管如何,只要重启 Job,都得保证它能继续上一次停止的地方继续前进,而不是重头开始。
保证系统能够断点续传,有两个必要条件:一是变更数据必须有一个类似于主键的用来标识其唯一性的值,以便于系统在重启后能够知道从哪里继续,这里管这个唯一的值为游标,二是系统必须能够持久化这个值,并且只能在数据被确认写入目的端后,才能保存这个值,否则可能发生数据丢失的风险。
那么如何实现呢?这里简单介绍两种方式,一种是在数据写入时,同时保存游标值,但是需要注意的写入端为多任务时,游标的顺序问题,如果仅保存一份游标值,那么必须保证它的值是有序的更新;二是参考 Storm 的 ACK 机制 + Kafka 的定时提交 offset 机制,系统在监听到数据变化时,注册 ACK 元祖,在写入完成后,响应对应的元祖,并由固定的监听程序来更新游标值,游标值更新在内存中,通过定时刷新游标值来将其刷新到磁盘,这样做的好处是,刷新游标几乎不会影响到数据写入的时间,但是不好的是,在系统停止时,游标值可能会落后更多,而导致数据发生更多的重发。具体如何实现,需要根据业务特点来做判断。
四、总结
上述主要围绕如何构建高效的数据同步模型,以及数据同步的过程中,关于数据一致性、时序性以及断点续传的问题来讨论,真正实现的过程中,需要注意的细节远比这里讨论的更多,后面在慢慢总结总结吧。
下面是了解到的几个开源的数据同步系统,如果能满足你的需求,就可以免得自己开发了: