SQLServer 数据异构实时同步之数据时序的问题
一、数据异构实时同步简介
数据异构实时同步是指将数据从源端数据库近实时的同步至目的端数据库的一个过程,比如将 SQLServer 中的数据同步至 HBase 或 Kafka 中。不同于离线同步,实时同步需要解决变更数据采集与数据时序等问题,以此保证数据的一致性。本文主要介绍以 SQLServer 为源端进行数据同步的过程中产生的数据时序相关的问题。

不同于 MySQL 可以通过解析 BinLog 的方式采集变更数据,在 SQLServer 中,由于其本身的特征,主要使用以下方式采集变更数据:
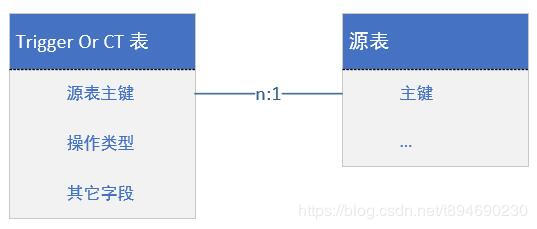
- Trigger:使用触发器将变更数据记录在一张单独的表中,通常仅记录源表主键及操作类型;
- CT:开启 CT,以记录数据的变更,包含事务信息及源表主键;
- CDC:开启 CDC,以记录数据的变更,包含全量数据;
CDC 由于需要太多的资源,所以仅考虑 Trigger 以及 CT 的方式,其大致流程为:通过 Trigger 或 CT 的方式获取到变更数据的主键,然后根据主键再去源表拿到源数据即可实现变更数据的获取。
二、数据时序的问题
在获取到变更数据后,数据需要写入目的端数据库并且同时推进游标(比如记录最后完成的主键或版本号等)才算完成了整个同步流程。
推进游标是为了程序在重启或发生故障后,能继续上一次结束的位置继续同步数据。如果仅仅是使用单线程,并且仅写入一个目的端且写入数据与游标推进是同步操作的情况,那么便不太可能会出现数据时序的问题。但现实中,我们很可能需要将一份源端的数据同步至多个目的端,并且为了提高吞吐量并减少数据的延迟,需要使用多线程以及利用流的特点来完成数据同步。此时便可能发生数据时序的问题。
数据时序的问题是指数据的操作能否按照在源端操作的顺序有序同步到目的端。比如针对 x=1 的数据,在源端进行了 x=2 以及 x=3 的两次操作,当它们被同步到目的端的时候,必须保证 x=2 的这次操作优先于 x=3 操作执行,才能保证目前端的数据最终为 x=3。如果 x=3 优先于 x=2 执行,那么目的端的数据将最终为 x=2,此时系统中的数据将处于不一致的状态。所以解决数据时序的问题的主要目的是要保证数据的一致性。
如果我们能在数据写入即使乱序也仍然能保证数据的一致性,那么数据时序的问题便不是问题。比如 HBase 可以利用 timestamp 来实现数据的幂等性更新。但是仍然会有系统需要保证数据的操作顺序是一致的,基于此,可将数据的顺序分为以下两种:
- 数据全局有序;
- 数据以主键为单位的有序;
数据全局有序是指数据的所有操作都按照先后顺序依次同步至目的端,这通常只能使用单线程完成,效率低下且应用场景较少。实际场景中,仅需要以 key(行)为单位,保证其有序,即可满足大部分应用场景,所以这里仅讨论数据以 key 为单位的有序的情况。
三、数据以主键为单位的有序
对于以下数据及其操作,我们仅需要保证每个主键对应的操作是有序的即可,即只要 { OP_1, OP_3, OP_5 } 与 { OP_2, OP_4 } 内部的先后顺序是一致的,即使 OP_2 优先与 OP_1 执行也没关系。
| id | 操作 |
|---|---|
| 1 | OP_1, OP_3, OP_5 |
| 2 | OP_2, OP_4 |
在确定此前提后,利用流式数据传输以及多线程 hash 分发数据,并结合 Kafka 的分片(partition)模型,便可实现一个高吞吐多并发的数据同步模型。
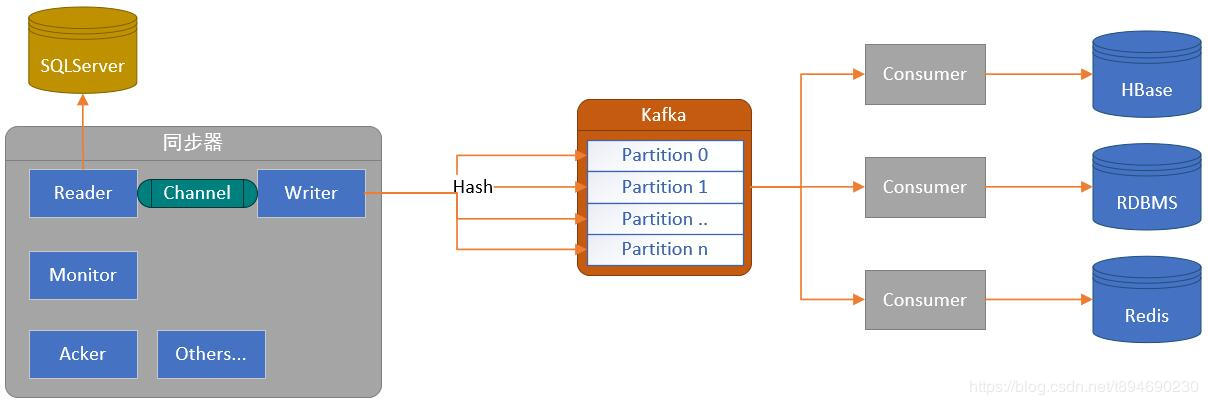
确定数据以主键为单位的有序性之后,还得面对一个问题,即数据操作被重复发送的问题。
四、数据操作被重复发送
在引入 kafka 后,数据先写入 kafka 再通过订阅端写入目的端。kafka 与订阅端会保证数据一定会写入目的端,所以游标的推进仅需要在数据写入至 kafka 之后便可更新。
数据被 hash 至不同的子线程后,每个子线程仅需保证该线程的数据写入顺序即可,并可通过同步写入数据与游标推进操作来保证每行数据的操作至多将最新的操作重复发送一次,如果每次重启仅仅是将最新的操作重发一次,那么在订阅端执行两次相同操作不会产生什么影响。但是在实际的项目中,我发现同步写入数据与游标推进操作会影响系统的同步效率,因为游标推进需要更新其它存储系统中的游标值。如果更新较为频繁即使系统交互之间的延迟即使不大,也会影响到同步效率。相同线程的情况下,速度慢3 ~ 4倍以上也是可能的。
所以如果每行数据即使被同时重复发送多次操作也不会影响数据的一致性,那么便可以将数据写入与游标推进更改为异步,通过异步 ack 机制来完成游标推进。
五、数据操作的重复发送与影响
假设有以下数据:
| id | x |
|---|---|
| 1 | 0 |
对 id=1 的数据有如下操作:
| 操作名 | 时间 | 更新 | 结果 x |
|---|---|---|---|
| OP_1 | t1 | x = 1 | 1 |
| OP_2 | t2 | x = 2 | 2 |
| OP_3 | t3 | x = 3 | 3 |
正常的情况下,数据同步的过程中会依次同步 OP_1、OP_2、OP_3 这三次操作,并依次(或合并)更新游标,这时反映在目的端的数据 x 的值也会依次被更新,并最终为 x=3。
| 操作名 | 时间 | 源数据 |
|---|---|---|
| OP_1 | t1 | id = 1, x = 1 |
| OP_2 | t2 | id = 1, x = 2 |
| OP_3 | t3 | id = 1, x = 3 |
但是如果数据在同步至目的端之后,游标未推进的情况下,系统发生异常被重启了,此时则会重新发送 OP_1、OP_2、OP_3 这三次操作。仅凭想象的话,也许我们会认为目的端的数据会被重新按照 1、2、3 的顺序被赋值,从而导致数据出现短暂的回退现象,运气再差点的话,OP_3 操作还未来得及执行,就被异常停止了,此时 x 的值将退回到 x=2,数据发生了错误。
但是实际上,由于使用 trigger 或 CT 的方式记录表的变更,它们仅包含源表的主键(或必要的信息),在获取到变更操作之后,需要再次到源表获取源数据,所以即使系统被重启,这三次操作所携带的源数据也应该是相同的:
| 操作名 | 时间 | 源数据 |
|---|---|---|
| OP_1 | t4 | id = 1, x = 3 |
| OP_2 | t4 | id = 1, x = 3 |
| OP_3 | t4 | id = 1, x = 3 |
此时反映到目的端的操作可能如下:
| 操作名 | 时间 | 源数据 |
|---|---|---|
| OP_1 | t1 | id = 1, x = 1 |
| OP_2 | t2 | id = 1, x = 2 |
| OP_3 | t3 | id = 1, x = 3 |
| OP_1 | t4 | id = 1, x = 3 |
| OP_2 | t4 | id = 1, x = 3 |
| OP_3 | t4 | id = 1, x = 3 |
可以发现对目的端数据无影响。同样的,引入删除操作也将会是同样的结论,正常情况下,每次操作携带的数据如下:
| 操作名 | 时间 | 源数据 |
|---|---|---|
| OP_1 | t1 | id = 1, x = 1 |
| OP_2 | t2 | id = 1, x = 2 |
| OP_3 | t3 | id = 1, x = 3 |
| OP_4 (DELETE) | t4 | null |
发生异常重启后,因为源数据已经被删除,所以它们将都会空:
| 操作名 | 时间 | 源数据 |
|---|---|---|
| OP_1 | t5 | null |
| OP_2 | t5 | null |
| OP_3 | t5 | null |
| OP_4 (DELETE) | t5 | null |
前提是:主键被删除后不可再恢复!
六、结论
数据异构同步的一个难点就在于保证数据的时序性,诸如 HBase 的多版本特征可以自主保证数据的一致性,其它如 Redis、Solr 等则可能需要由同步器保证数据同步写入的顺序。而得知在一些场景下,数据操作可以在系统被重启后被重复发送,有助于改善游标推进的实现,因为同步更新游标极可能会影响到数据同步的性能,而游标的主要目的是用于保证系统在异常或正常重启后能够继续上一次同步的位置继续同步,但是对于一个实时在线同步的系统而言,被重启的情况本就是很少的。
注:以上分析仅针对以 SQLSever 为源端的数据同步的特定场景,不能概括所有场景。