DataX 中流的速度限制原理
概述
这里的流的速度限制是指在单位时间窗口内,最多允许指定的单位数据通过。比如我们需要从源端 A 发送 1000 条数据到目的端 B,如果设置的速度限制为最多 100 条每秒,那么理论上需要 10 秒的时间才能将数据传输完成,即使当前的网络允许在极短的时间便完成这个任务。
但是我们没办法严格控制每秒时间内的数量一定是小于等于 100 的,因为我们不能每传输一条数据便进行速度与其控制的计算,这样会极大的带来性能的损耗。
所以这里引入时间窗口的概念,因为我们希望能够通过计算一个时间窗口内的速度,来判断是否需要进行速度控制。如果该时间窗口内的速度大于阈值,那么便通过睡眠一定的时间,来使更长时间上的平均速度是不高于阈值的。比如一个时间窗口的大小为 1s,阈值仍为 100 条每秒,那么如果在这 1s 以内传输了 300 条数据,则需要等待 2s 以后才能继续进行数据传输。这样,即使在前 1s 速度超过了阈值(300 > 100),但是因为后 2s 的速度为 0,所以从整体上来看,这 3s 的的平均速度仍然是不高于阈值的。最终它的速度走势也许会类似下图:
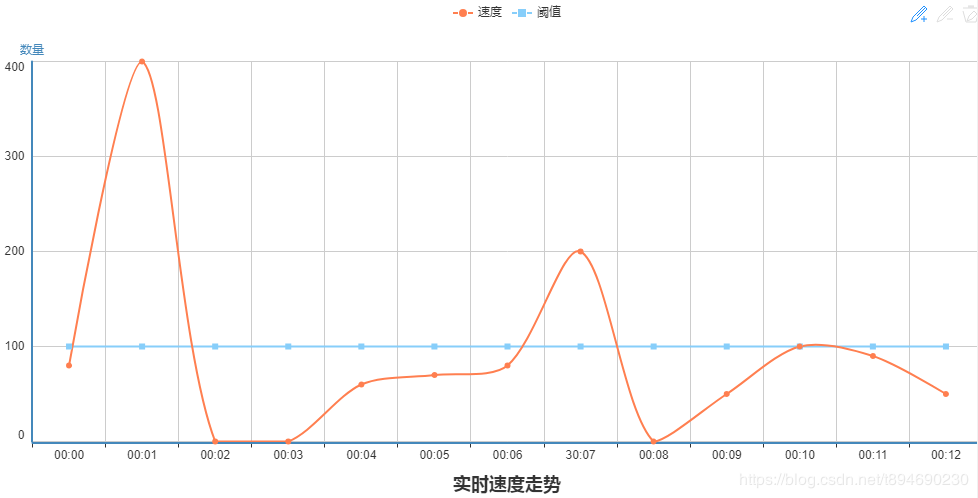
可以看见,虽然阈值为 100 条每秒,但是仍然会有部分时间窗口内的总量超过阈值,不过通过限制之后时间内的速度,从而使整体平均的速度是不高于阈值的。
公式
根据前面概述,可推理出公式。设置一下变量:
- 时间窗口的时间间隔为:flowControlInterval(单位:毫秒)
- 实际时间间隔为:interval(单位:毫秒)
- 实际时间间隔内传输的数据总量为:numResults(单位:条)
- 最大限制速度为:maxSpeed(单位:条/秒)
- 当前速度为 currentSpeed(单位:条/秒)
- 等待休眠的时间为:limitSleepTime(单位:毫秒)
那么已知 flowControlInterval、interval、numResults 的值,可得到:
当前速度:
currentSpeed = numResults * 1000 / interval;
睡眠时间:
limitSleepTime = currentSpeed * interval / maxSpeed - interval;
使用 Java 代码表示大致如下:
long interval = nowTimestamp - lastTimestamp;
if (interval >= flowControlInterval) {
long numResults = totlaResults - lastResults;
long currentSpeed = numResults * 1000 / interval;
if (currentSpeed > maxSpeed) {
// 计算休眠时间
limitSleepTime = currentSpeed * interval / maxSpeed - interval;
}
if (limitSleepTime > 0) {
Thread.sleep(limitSleepTime);
}
}
这里的 nowTimestamp、totlaResults 为当前时间的时间戳与当前总共传输的数据总量,lastTimestamp、lastResults 为上一次计算后记录的时间的时间戳与数据传输总量,通过计算可得到实际的时间间隔与该时间段内的数据传输量。
注:以上算法与代码均参考于阿里的开源项目 DataX,源码路径:https://github.com/alibaba/DataX/blob/master/core/src/main/java/com/alibaba/datax/core/transport/channel/Channel.java#L192。
总结
通过以上方式限制流的速度,可以对包括数量、字节大小等所有可以量化的指标进行限制,虽然不能保证每一个单位时间内的速度总是不高于阈值,但是却能使平均的速度是不高于阈值的。
参考
- DataX: https://github.com/alibaba/DataX