Hadoop 原理学习(8)Yarn 概述及其基本原理
[TOC]
一、Yarn 简介
Yarn 是 hadoop 集群的资源管理层。它允许不同的数据处理引擎(如图形处理、交互式 SQL、流处理、批处理)运行在 hadoop 集群中并处理 HDFS 中的数据(移动计算而非数据)。除了资源管理外,Yarn 还用于作业调用。
从资源管理方面看,Yarn 管理着由各个 NodeManager 节点的 vcore(CPU内核)和 RAM(运行时内存)共同组成的一组资源,比如我们的一个集群由35个 NodeManager 节点共560 vcores 和 3.4TiB的内存组成,那么 Yarn 管理的资源大小便是560 vcores + 3.4TiB RAM。当我们提交一个应用程序到 hadoop 集群时,Yarn 便会为这个应用程序分配一个资源池,这个资源池包含一定数量的 containers,每个 container 又包含一定数量的 vcores 和内存供应用程序运行。
二、Yarn 组件
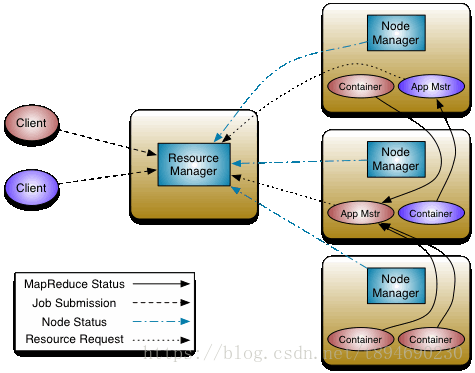
Yarn 采用传统的 master-slave 架构模式,其主要由 4 种组件组成,它们的主要功能如下:
- ResourceManager(RM):全局资源管理器,负责整个系统的资源管理和分配;
- ApplicationMaster(AM):负责应用程序(Application)的管理;
- NodeManager(NM):负责 slave 节点的资源管理和使用;
- Container(容器):对任务运行环境的一个抽象。
ResourceManager (RM)
ResourceManager 是一个全局的资源管理器,负责整个系统的资源管理和分配。它主要由两个组件组成:
- Scheduler:资源调度器,主要功能和特点如下:
- 负责将资源分配给各种正在运行的应用程序,这些应用程序受到容量、队列等限制;
- Scheduler 是纯调度程序,不会监视或跟踪应用程序的状态;
- 由于应用程序故障或硬件故障,它不提供有关重新启动失败任务的保证;
- Scheduler 根据应用程序的资源需求来执行其调度功能,它是基于资源容器的抽象概念来实现的,容器(Container)内包含内存、CPU、磁盘、网络等因素;
- Scheduler 是一个可插拔的插件(即可配置),负责在各种队列、应用程序等之间对集群资源进行区分。当前支持的Scheduler类包括:FairScheduler、FifoScheduler、CapacityScheduler;
- Applocation Manager:负责接受 job 提交请求,为应用程序分配第一个 Container 以运行 ApplicationMaster,并提供失败时重新启动运行着 ApplicationMaster 的 Container 的服务。
ApplicationMaster(AM)
当用户提交一个应用程序时,将启动一个被称为 ApplcationMaster 的轻量级进程的实例,用以协调应用程序内所有任务的执行。它的主要工作包括:
- 向 ResourceManager 申请并以容器(Container)的形式提供计算资源;
- 管理在容器内运行的任务:
- 跟踪任务的状态并监视它们的执行;
- 遇到失败时,重新启动失败的任务;
- 推测性的运行缓慢的任务以及计算应用计数器的总值。
NodeManager(NM)
NodeManager 进程运行在集群中的节点上,是每个节点上的资源和任务管理器。它的主要功能包括:
- 接收 ResourceManager 的资源分配请求,并为应用程序分配具体的 Container;
- 定时地向 ResourceManager 汇报本节点上的资源使用情况和各个 Container 的运行状态,以确保整个集群平稳运行;
- 管理每个 Container 的生命周期;
- 管理每个节点上的日志;
- 接收并处理来自 ApplicationMaster 的 Container 启动/停止等请求。
Container(容器)
Container 是 Yarn 中的资源抽象,是执行具体应用的基本单位,它包含了某个 NodeManager 节点上的多维度资源,如内存、CPU、磁盘和网络 IO,当然目前仅支持内存和 CPU。
任何一个 Job 或应用程序必须运行在一个或多个 Container 中,在 Yarn 中,ResourceManager 只负责告诉 ApplicationMaster 哪些 Containers 可以用,ApplicationMaster 需要自己去找 NodeManager 请求分配具体的 Container。
Container 和集群节点的关系是:一个节点会运行多个 Container,但一个 Container 不会跨节点。
三、提交任务流程
客户端向RM提交任务流程
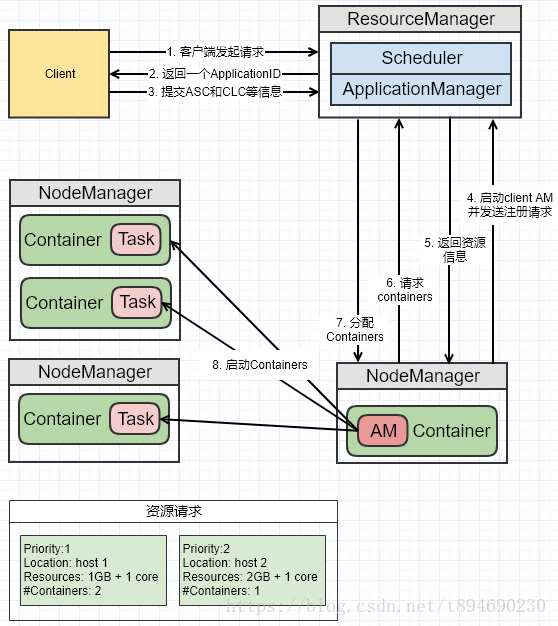
说明:
- 客户端向 RM 发出请求;
- RM 返回一个 ApplicationID 作为回应;
- 客户端向 RM 回应 Application Submission Context(ASC)和 Container Launch Context(CLC)信息。其中 ASC 包括 ApplicationID、user、queue,以及其它一些启动 AM 相关的信息,CLC 包含了资源请求数(内存与CPU),Job 文件,安全 token,以及其它一些用于在 NM 上启动 AM的信息;
- 当 ResourceManager 接受到 ASC 后,它会调度一个合适的 container 来启动 AM,这个 container 经常被称做 container 0。AM 需要请求其它的 container 来运行任务,如果没有合适的 RM,AM 就不能启动。当有合适的 container 时,RM 发请求到合适的 NM 上,来启动 AM。这时候,AM 的 PRC 与监控的 URL 就已经建立了;
- 当 AM 启动起来后,RM 回应给 AM 集群的最小与最大资源等信息。这时 AM 必须决定如何使用那么当前可用的资源。YARN 不像那些请求固定资源的 scheduler,它能够根据集群的当前状态动态调整;
- AM 根据从 RM 那里得知的可使用的资源,它会请求一些一定数目的 container。这个请求可以是非常具体的包括具有多个资源最小值的 Container(例如额外的内存等);
- RM 将会根据调度策略,尽可能的满足 AM 申请的 container;
- AM 根据分配的信息,去找NM启动对应的 container。
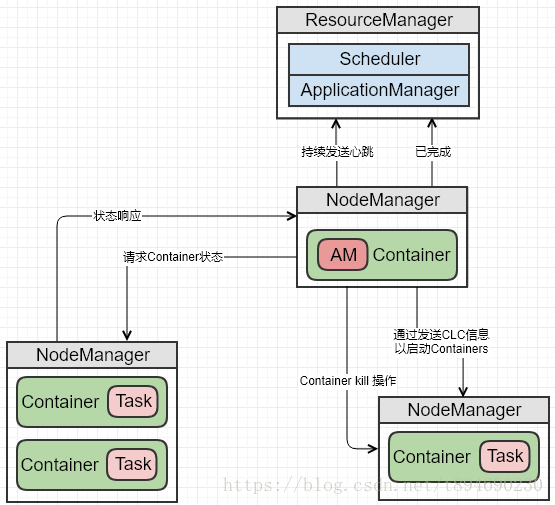
运行状态交互
当一个任务运行时,AM 会向 RM 汇报心跳与进度信息,在这些心跳过程中,AM 可能会去申请或者释放 Container。当任务完成时,AM 向 RM 发送一条任务结束信息然后退出。AM 与 RM 交互的示例如下图:
四、总结
与 HDFS/HBase 一样,Yarn 也使用了简洁的 master-salve 架构,这不仅更容易让人理解它的运行原理,也更方便了运维人员对集群的管理,仿佛《道德经》中提到的“万物之始,大道至简,衍化至繁”一样。同时,将集群的资源抽象,这也可作为将面向对象思想运用的一个经典示例,毕竟,一切皆对象 For Java。
五、参考链接
注:此文章主要为学习的笔记,其中大量的翻译了参考链接中的资料,并有改动,如有需要,请阅读原文。