Hadoop 原理学习(6)HBase 架构与工作原理4 - 压缩、分裂与故障恢复
Compacation
HBase 在读写的过程中,难免会产生无效的数据以及过小的文件,比如:MemStore 在未达到指定大小便刷新数据以写入到磁盘;或者当已经写入 HFile 的数据被删除后,原数据被标记了墓碑,却仍然存在于 HFile 之中。在这些情况之下,我们需要清除无效的数据或者合并过小的文件来提高读的性能。这种合并的过程也被称为 compacation。
HBase 中使用的 compacation 方式主要分为以下两种:
- Minor_compaction
- Major_compaction
Minor_Compaction
HBase 会自动选择一些较小的 HFile,并将它们重写成更少的但更大的 HFiles 文件,这个过程被称为 minor_compaction。minor_compaction 通过将少量的相邻的 HFile 合并为单个 HFile 来达到压缩操作,但是它不会删除被标记为删除或过期的数据。
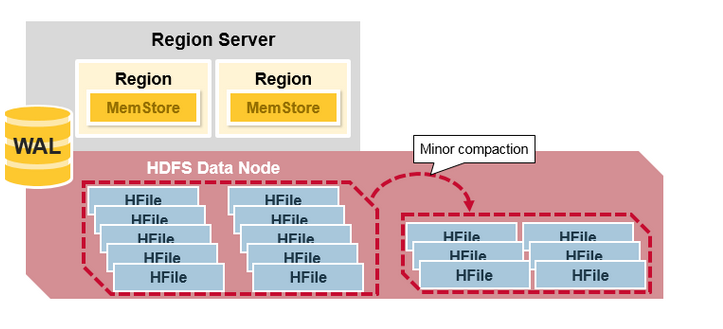
Major_Compaction
Major_Compaction 将 Region 中的所有 HFile 合并并重写成一系列由列族(Column Family)组成的 HFile 文件,并在此过程删除已被删除或已过期的数据。这会提高读取性能,但是由于 Major_compaction 会重写所有文件,所以在此过程中可能会发生大量的磁盘 I/O 和网络流量,这种现象被称为写入放大(write amplification)。
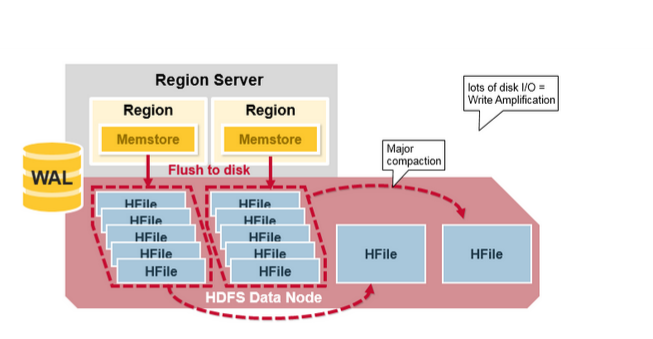
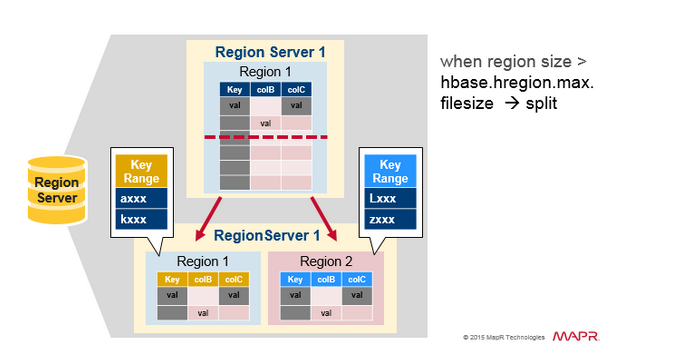
Region Split
最初,每一个 table 都会有一个 Region。随着数据的不断写入,当这个 Region 变得太大时,它就会被分裂成两个子 Regions。两个子 Regions 各种拥有原 Region 的一半,它们会在相同的 RegionServer 上并行打开,然后将分区信息报告给 HMaster。处于负载均衡的原因,HMaster 可能会将新的 Region 移动到其它服务器。
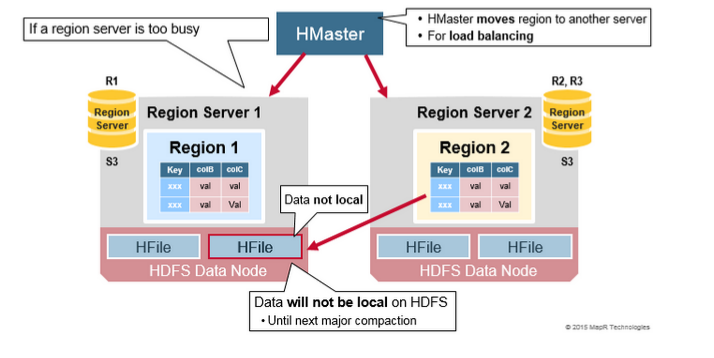
负载均衡
Split 最初发生在同一个 RegionServer 上,但是出于负载均衡的原因,HMaster 可能会将新的 Region 移动到其它服务器(移动元数据,而不是 HFile 文件)。这会导致新的 RegionServer 提供来自远程 HDFS 节点的数据,直到 Major_compaction 时将数据文件移动到区域服务器的本地节点。
故障恢复
WAL 文件和 HFile 被保存在磁盘上并被复制,但是 MemStore 还没有被保存在磁盘上,所以当 RegionServer 发生问题后,HBase 是如何恢复 MemStore 之中的数据呢?
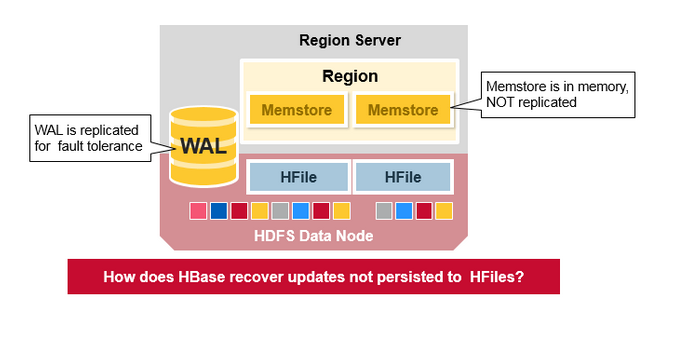
当 RegionServer 失败时,崩溃的 Region 将不可用,直到检查并恢复之后方可继续使用。Zookeeper 会在失去 RegionServer 心跳时确定节点故障,HMaster 将会被通知 RegionServer 已经失败。
注:当 RegionServer 失败时,正在查询该节点上的数据的操作会被重试,并且不会立即丢失。
当 HMaster 检测到 RegionServer 已经崩溃时,HMaster 会将已崩溃的 RegionServer 上的 Regions 重新分配给活动的 RegionServer。为了恢复已崩溃的 RegionServer 上未刷新到磁盘的 MemStore 中的内容,HMaster 将属于崩溃的 RegionServer 的 WAL 文件拆分成单独的文件,并将这些文件存储在新的 RegionServer 的 DataNode 上。然后新的 RegionServer 根据拆分后的 WAL 文件重播 WAL,以重建丢失的 MemStore 区域。
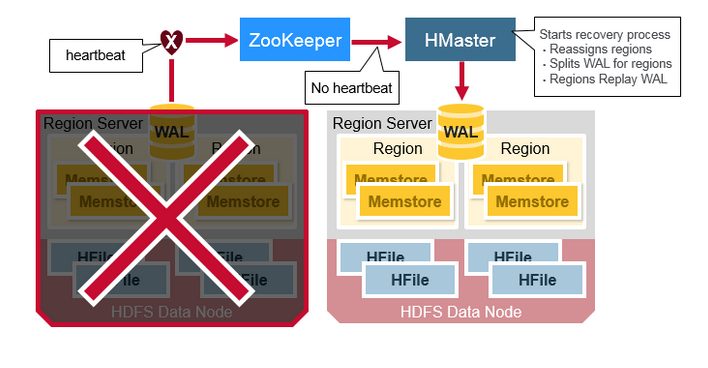
WAL 重播
WAL 文件包含编辑列表,一个编辑表示单个操作的 put 或者 delete。编辑按照时间顺序写入,并将附加到存储在磁盘上的 WAL 文件的末尾。
如果数据仍在 MemStore 中并且未保存到 HFile 中时,将发生 WAL 重播。WAL 重播是通过读取 WAL 文件,将其包含的编辑操作添加到当前的 MemStore 并进行排序来完成的。
参考链接
注:此文章主要为学习的笔记,其中大量的翻译了参考链接中的资料,并有改动,如有需要,请阅读原文。