Spark _on_Yarn 资源池内存限制测试报告 - 防止“非法”任务的提交
需求背景
讲道理,用户在提交 Spark_on_yarn 任务 时,应该指定--executor-memory属性(公司自己的规定),并且使用特定的用户提交,以便于 DBA 的管理。但是仍然存在一些用户直接使用 root 账户提交任务,这样在 yarn 的资源池中就会被分配到 root.user.root池中,如果集群压力过大,那么便不能迅速的找到该任务 的所有者,从而可能会对其它 team 的任务照成影响,基于此, 决定对资源池root.user.root进行内存限制,为了防止确定其是否有用,同时防止直接修改线上环境配置会对已有的任务造成的影响,特做此简单的测试。
环境配置
环境:
- yarn 2.6.0+cdh5.8.3+1718
- spark_on_yarn 1.6.0+cdh5.8.3+232
工具:
- Cloudera Manager
可执行文件:
- 自定义 jar 包,最终生成的名称为
spark-mock-0.0.1-SNAPSHOT.jar,源码如下:
package com.xxx.xxx.sparkmock;
import java.util.ArrayList;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
public final class JavaSparkPi {
@SuppressWarnings("serial")
public static void main(String[] args) throws Exception {
SparkConf sparkConf = new SparkConf().setAppName("JavaSparkPi");
JavaSparkContext jsc = new JavaSparkContext(sparkConf);
int slices = 2;
int n = 100000 * slices;
List<Integer> l = new ArrayList<Integer>(n);
for (int i = 0; i < n; i++) {
l.add(i);
}
JavaRDD<Integer> dataSet = jsc.parallelize(l, slices);
int count = dataSet.map(new Function<Integer, Integer>() {
public Integer call(Integer v1) {
double x = Math.random() * 2 - 1;
double y = Math.random() * 2 - 1;
return (x * x + y * y < 1) ? 1 : 0;
}
}).reduce(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer v1, Integer v2) {
return v1 + v2;
}
});
System.out.println("Pi is roughly " + 4.0 * count / n);
jsc.stop();
}
}
测试流程:
1. 将 jar 包拷贝至 hadoop 集群,使用类似如下格式执行:
spark-submit --master yarn --executor-memory 512M ~/spark-mock-0.0.1-SNAPSHOT.jar
提交用户默认为 kt94(登录)
- –master 指定任务基于 yarn 工作
- –executor-memory 执行时的内存大小
2. 在 Cloudera Manager 中,配置资源池的容量大小,界面示例如下:
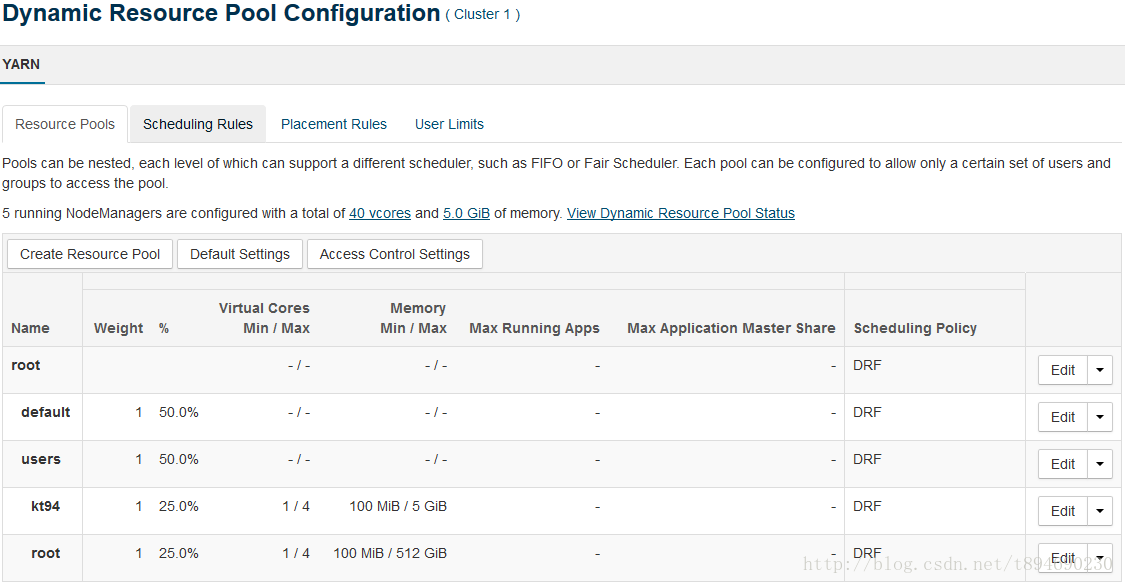
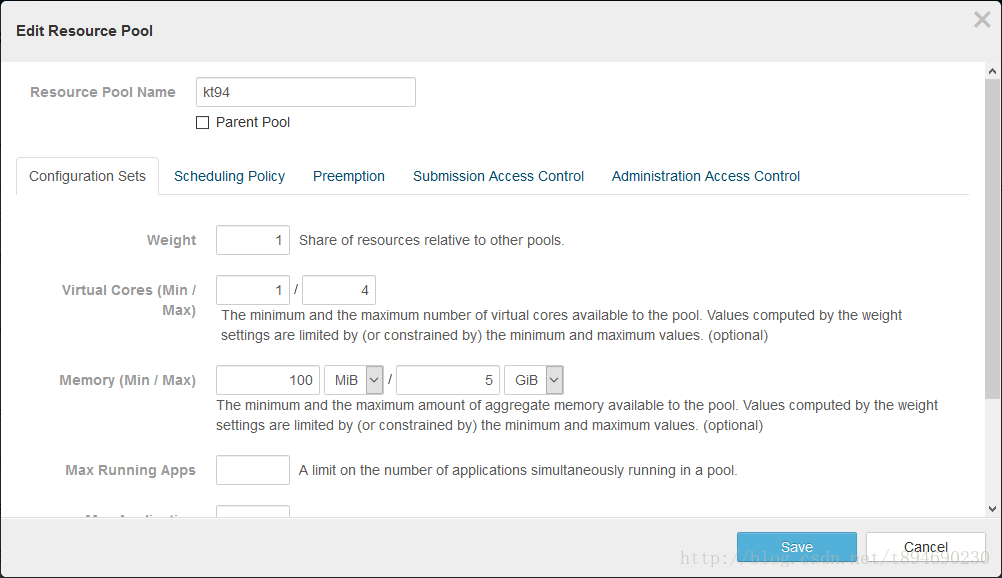
3. 反复提交执行与更改配置,并观察结果
测试结果
注 1:以下测试仅测试提交时申请的 AM 内存大小与配置的最大内存大小关系,暂未考虑权重(Weight)的影响,后面总结会提到权重。
注 2:--executor-memory是指定的执行内存,但是因为存在额外的管理开销,所以实际的AM 使用内存会大于--executor-memory指定的值,而配置的内存限制的是AM 的使用内存,所以下方比较的是AM memory和max memory(限制的最大内存)。
1. 默认情况下,即不指定--executor-memory时,会抛出以下异常:
// ...
java.lang.IllegalArgumentException: Required executor memory (1024+384 MB) is above the max threshold (1024 MB) of this cluster! Please check the values of 'yarn.scheduler.maximum-allocation-mb' and/or 'yarn.nodemanager.resource.memory-mb'.
// ...
这是由于测试环境的配置引起的,因为请求时默认的executor-memory值为1 GB,加上运行时所需的额外的384 MB,超出了阈值 1024 MB,所以抛出了异常,但是正式环境下,不会有这么小的阈值,所以把--executor-memory设置为更小的值继续观察。
2. 提交时指定--executor-memory=512M,资源池kt94设置Memory (Min / Max) ~= 100MiB / 5GiB时,即AM memory < max memory时,运行正常,资源池使用情况如下图:
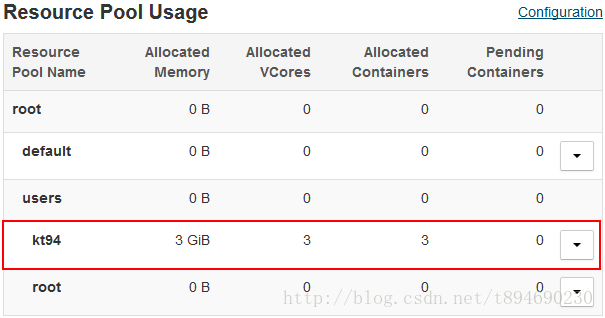
AM 被分配3GiB的容量,小于5GiB
3. 提交时指定--executor-memory=512M,资源池kt94设置Memory (Min / Max) ~= 100MiB / 256MiB时,即AM memory > max memory时,任务一直处于ACCEPTED状态,部分打印信息如下:
18/01/19 00:33:39 INFO yarn.Client: Application report for application_1512525158468_0035 (state: ACCEPTED)
18/01/19 00:33:40 INFO yarn.Client: Application report for application_1512525158468_0035 (state: ACCEPTED)
18/01/19 00:33:41 INFO yarn.Client: Application report for application_1512525158468_0035 (state: ACCEPTED)
18/01/19 00:33:42 INFO yarn.Client: Application report for application_1512525158468_0035 (state: ACCEPTED)
18/01/19 00:33:43 INFO yarn.Client: Application report for application_1512525158468_0035 (state: ACCEPTED)
18/01/19 00:33:44 INFO yarn.Client: Application report for application_1512525158468_0035 (state: ACCEPTED)
18/01/19 00:33:45 INFO yarn.Client: Application report for application_1512525158468_0035 (state: ACCEPTED)
18/01/19 00:33:46 INFO yarn.Client: Application report for application_1512525158468_0035 (state: ACCEPTED)
18/01/19 00:33:47 INFO yarn.Client: Application report for application_1512525158468_0035 (state: ACCEPTED)
18/01/19 00:33:48 INFO yarn.Client: Application report for application_1512525158468_0035 (state: ACCEPTED)
同时资源池kt94,该任务 一直在Pending Containers(待定的容器)中,资源池状态示例如下图所示:
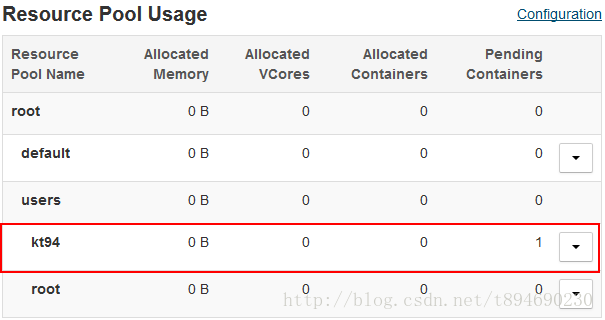
任务简介如下图所示:

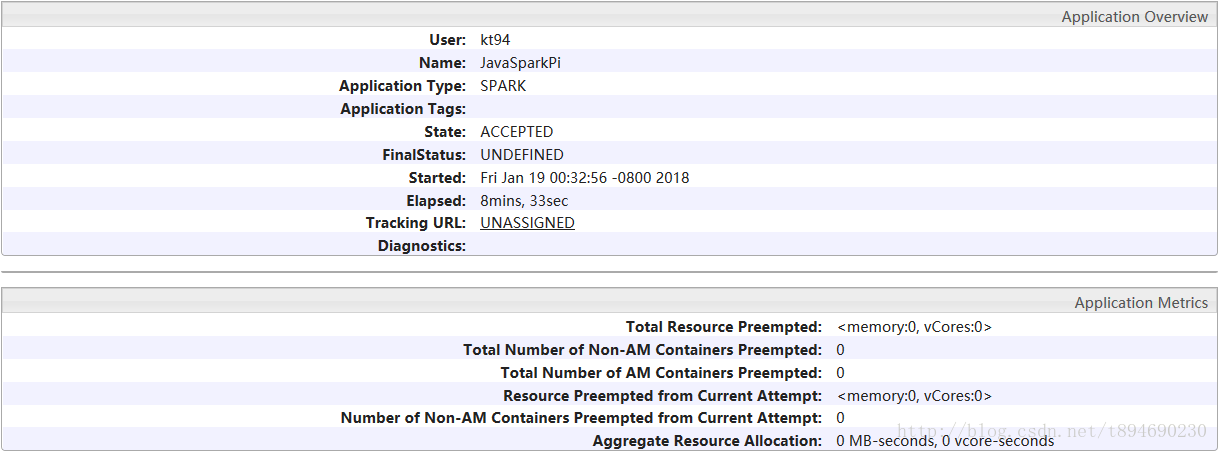
此时并未分配内存给该任务,而该任务则一直处于ACCEPTED状态,说明配置是生效的。
4. 重新配置使Memory (Min / Max) ~= 100MiB / 5GiB,处于ACCEPTED状态的任务被分配到足额的内存,继续执行。
5. 对正在运行中,即已经分配到内存后,设置更小的内存限制,原先的任务不受影响。
6. 将账号kt94更改为root结果同上。
总结
经过反复测试,可以得出使用如下步骤可防止用户滥用root账户(sudo 提交时,默认为 root 账户)提交 spark_on_yarn 任务:
- 新建与 root 账户同名的资源池:root.users.root
- 设置 Memory(Min / Max) 的值,使其最大值略小
这样用户在使用root账户提交任务时,如果出现申请的资源过大,那么便不能继续执行,此时就只能找 DBA 解决了,然后就可以让他们按规范办事了。
最后: 根据动态资源池的原理:如果一个池的资源未被使用,它可以被占用(preempted)并分配给其他池,即是说,如果在初始时出现几个资源池同时出现需要额外内存的情况下,会根据它们的权重来分配内存容量:
比如,资源池 businessA 和 businessB 的权重分别为 2 和 1,这两个资源池中的资源都已经跑满了,并且还有任务在排队,此时集群中有 30 个 Container 的空闲资源,那么,businessA 将会额外获得 20 个 Container 的资源,businessB 会额外获得 10 个 Container 的资源。
所以即使没能在初始时限制“非法”的任务被提交,通过将权重的值设置相对更小,仍然可减少对其它任务的影响。